
«Я здаюся». Нейронні мережі не впоралися з недільними загадками – ForkLog UA

Колектив дослідників використовував щотижневу колонку головоломок Вілла Шорца з NPR, щоб оцінити здатність «роздумувати» моделей штучного інтелекту.
Фахівці з різних американських коледжів та університетів за сприяння стартапу Cursor розробили стандартизований тест для моделей ШІ, використовуючи головоломки з епізодів Sunday Puzzle. Команда вказує, що дослідження виявило інтригуючу інформацію, включно зі спостереженням про те, що чат-боти час від часу «здаються» та навмисно дають неправильні відповіді.
Sunday Puzzle — це щотижнева радіовікторина, де слухачам задають запитання, пов’язані з логікою та синтаксисом. Хоча вирішення цих головоломок не потребує спеціальних теоретичних знань, воно потребує критичного мислення та здібностей до аргументації.
Арджун Ґуха, один із співавторів дослідження, поділився з TechCrunch перевагами використання підходу «загадки», зазначивши, що він не оцінює езотеричні знання, а те, як сформульовано завдання, ускладнює моделям ШІ покладатися на «механічну пам’ять».
«Ці головоломки є складними, тому що суттєвого прогресу важко досягти, доки не буде знайдено рішення — саме тоді [остаточна відповідь] приходить разом. Це потребує поєднання інтуїції та процесу усунення», — заявив він.
Тим не менш, Гуха вказав на обмеження методу — Sunday Puzzle обслуговує англомовну аудиторію, а головоломки є загальнодоступними, що дозволяє ШІ потенційно «шахраювати». Дослідники планують покращити тест за допомогою додаткових головоломок, які наразі містять близько 600 завдань.
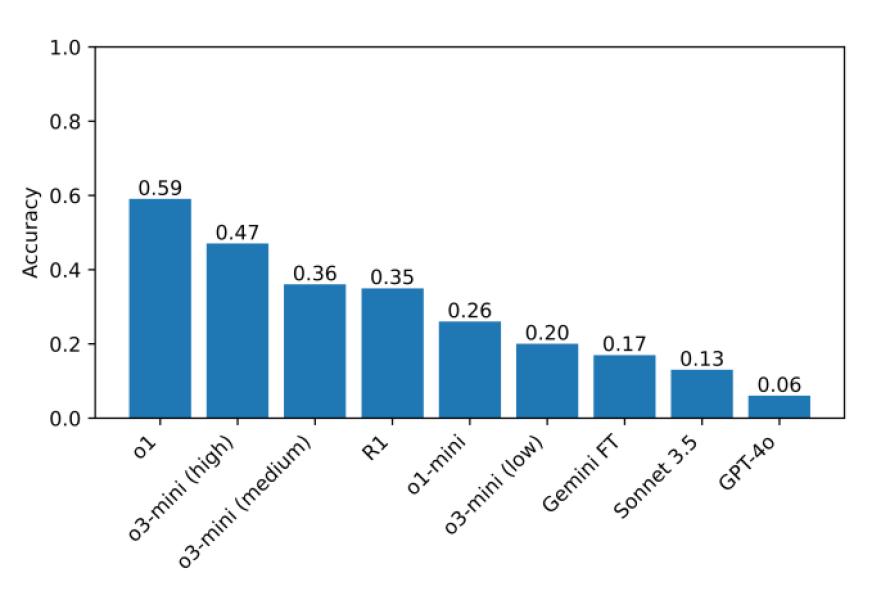
У проведених тестах o1 і DeepSeek R1 помітно перевершили інші моделі за своїми можливостями міркування. Провідні нейронні мережі проводили ретельну самоперевірку перед наданням відповідей, але цей процес зайняв значно більше часу, ніж зазвичай.

Модель зі штучним інтелектом отримує результати в тесті Sunday Puzzle. Джерело: TechCrunch.
Однак точність моделей ШІ не перевищувала 60%. Деякі моделі вирішили не братися за жодні головоломки. Коли нейронна мережа DeepSeek не могла визначити правильну відповідь, вона виражала «Я здаюся» під час процесу міркування, згодом надаючи неправильну відповідь, ніби її було вибрано випадковим чином.
Інші моделі кілька разів намагалися виправити попередні помилки, але зрештою не вдалося. ШІ часто здавалося «застряглим у думках», виробляючи безглузді результати та час від часу приходячи до правильних відповідей лише для того, щоб пізніше їх відхилити.


«Розчарована» відповідь R1 DeepSeek. TechCrunch.
«У складних завданнях R1 DeepSeek прямо заявляє, що він «розчарований». Цікаво спостерігати, як модель імітує те, що може передати людина. Залишається визначити, як «розчарування» в міркуваннях може вплинути на якість результатів моделі», – зазначив Гуха.
Раніше дослідник оцінив сім відомих чат-ботів у змаганні з шахів. Жодній з нейронних мереж не вдалося повністю освоїти гру.


